

By: Mason Prewett
Microsoft Fabric offers three methods for data integration solutions:
- Data Pipelines
- Dataflow Gen2
- Fabric Notebooks

These methods can perform similar data integration actions, which can lead to confusion when selecting one for a solution. In this article, we will look at each technology and present their unique strengths, limitations, and ideal solution requirements.
Microsoft Fabric Data Integration – Data Pipelines
Data pipelines offer the ability to create a process flow for data integration solutions that support the execution of activities sequentially or in parallel. This will be familiar to developers who have experience with using SQL Server Integration Services (SSIS) and Azure Data Factory (ADF), as Data Pipelines is the successor technology to both of these.
Data Pipeline Example Solution
The image below is a screenshot of a data integration solution using data pipelines:
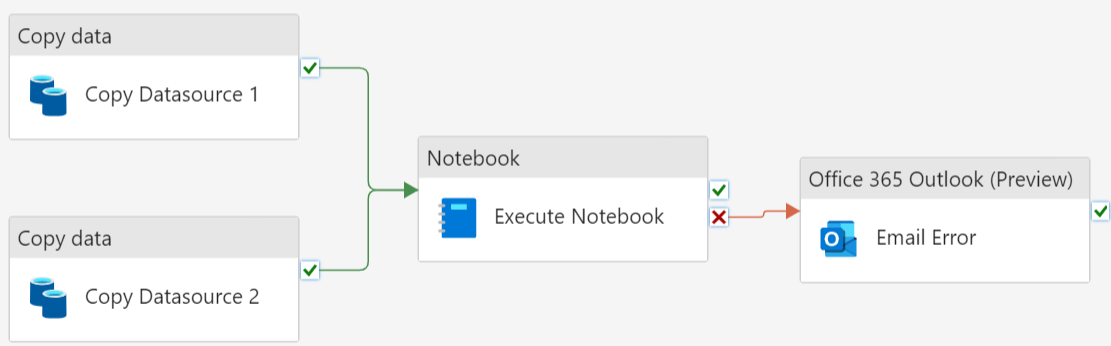
Here’s a high-level description of each step in the solution:
- Using two Copy activities in parallel to copy data from Datasource 1 and Datasource 2 to a storage location.
- Executing a Fabric notebook that then performs some logic. This would usually be to transform the data that was just copied.
- An Outlook activity is then connected to the On Fail path of the notebook. This will send an email if the notebook encounters an error.
Advantages of Data Pipelines
There are some powerful capabilities that data pipelines offer to a solution like this, such as:
- Low-Code/No-Code – data pipelines provide a low-code/no-code development experience, which means almost all development can be achieved using a user interface with drag-and-drop mechanics. This requires little to no coding experience and can cut development time significantly by eliminating the need to code basic operations.
- Copy Activity – the copy activity will copy the contents of a data source as-is to a defined destination. This activity is simple and quick to set up. It also provides the best performance for copying data from one location to another and it performs well with large datasets.
- Parameters – data pipelines and activities can be configured to accept parameters for each execution. This allows pipelines to be reused and executed with provided values.
- Activities – data pipelines provide many activities that can be used to create a data-driven workflow. Some examples of data integration activities that can be triggered include Databricks, stored procedures, Dataflow Gen2, and Fabric Notebooks.
- Error Handling – using the “On Fail” path of an activity, the developer can choose what action to take in the event of an activity error.
- Scheduling and Monitoring – data pipelines offer the most robust functionality for scheduling processes and monitoring process executions.
Limitations of Data Pipelines
There are also some limitations of data pipelines, such as:
- Low-Code/No-Code – while a low-code/no-code tool can be powerful for those with little to no coding experience, it can also be a limitation of capabilities. The ability to develop complex functionality is limited by the predefined activities provided in data pipelines.
- No Native Transformations – there is no method of doing transformations natively in data pipelines. The copy activity only copies data from one location to another and cannot perform any transformations. A data pipeline can only trigger an activity that can perform transformations, like Dataflow Gen2 or Fabric Notebooks.
Ideal For: Data-driven solutions that require a workflow approach and need the ability to trigger a wide variety of activities. Data pipelines provide the easiest and fastest method of copying data but cannot natively apply any transformations. Data pipeline solutions will provide the best scheduling, monitoring, and error handling.
Microsoft Fabric Data Integration – Dataflow Gen2
Dataflows Gen2 in Fabric is a data integration tool that allows multiple data sources to be combined, transformed, and refreshed. A data destination can be set that will automatically update the defined location with the contents of the dataflow when executed. This will be familiar to Power BI developers as the interface is similar to the Power Query transformation experience in Power BI Desktop.
Dataflow Gen2 Example Solution
The image below is a screenshot of a data integration solution using Dataflow Gen2:
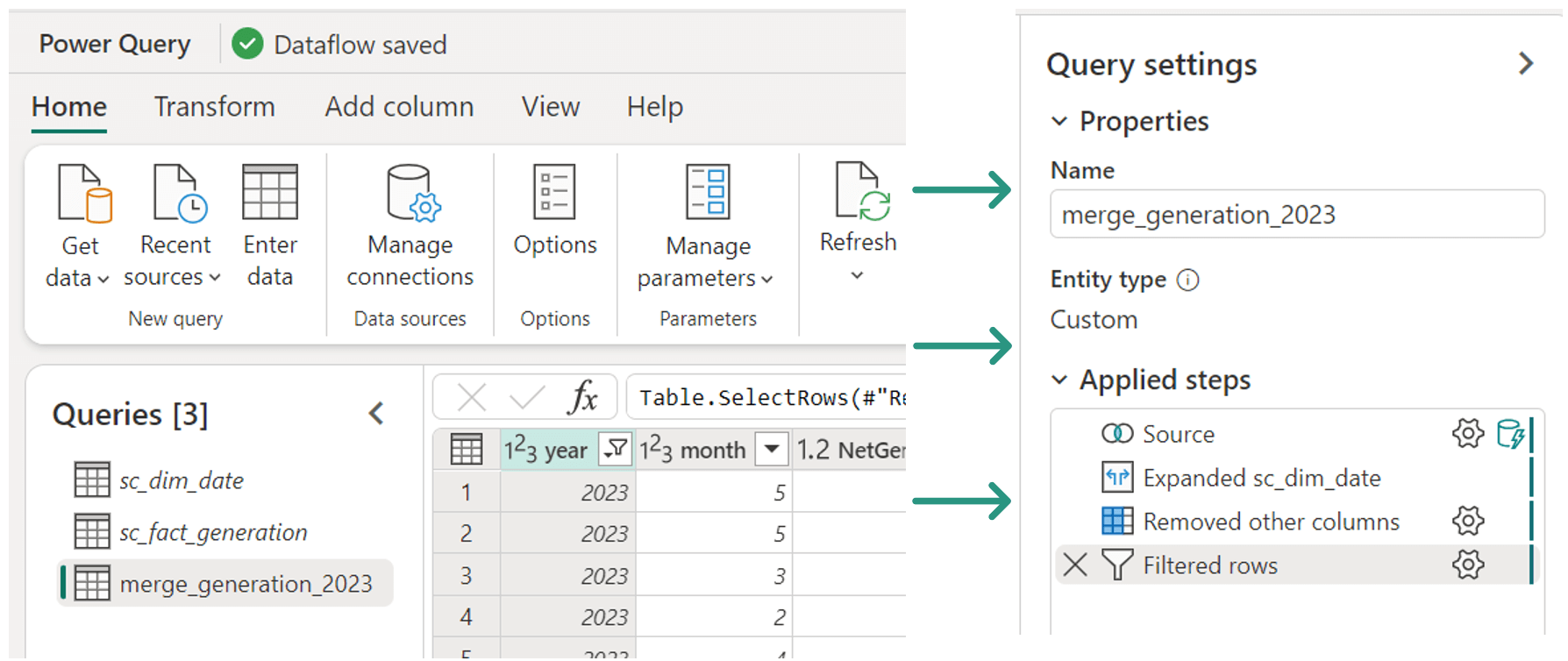
Here’s a high-level description of each step in the solution:
- sc_dim_date is being imported from a Fabric data warehouse.
- sc_fact_generation is being imported from a Fabric lakehouse.
- merge_generation_2023 is a query that joins sc_dim_date and sc_fact_generation to form a new result set with business logic applied.
- The transformation steps can be seen in the query settings.
- Source: inner join.
- Expand the joined date table and remove unwanted columns.
- Filter results.
Advantages of Dataflow Gen2
Dataflow Gen2 offers many powerful capabilities for data integration solutions, such as:
- Low-Code/No-Code – Dataflow Gen2 also provides a low-code/no-code option for development, which means almost all development can be achieved using a user interface with drag-and-drop mechanics. This requires little to no coding experience and can cut development time significantly by eliminating the need to code basic operations.
- M Code – Dataflow Gen2 uses the Power Query experience to achieve data ingestion and transformations. This also makes the Power Query formula language “M” available for developers to write custom code to achieve more complex functionality.
- Familiar Interface – the Power Query interface has been around for a long time and will be familiar to those with Power BI development experience.
- Transformations – Dataflow Gen2 excels at its ability to apply native transformations to ingested data using low-code/no-code or M code strategies.
Limitations of Dataflow Gen2
There are also some limitations of Dataflow Gen2, such as:
- Large datasets – Dataflow Gen2 does not perform as well as other options when refreshing larger datasets.
- Scheduling – rather than scheduling a workflow process, Dataflow Gen2 is refreshed using a schedule. This does not allow for any additional activities to be triggered as part of a process.
- Error Handling – Dataflow Gen2 does not have any way to handle errors that occur during a refresh. It will just show as failed and provide an error message.
- Logic Reuse – there isn’t a way to reuse logic that was already created in a Dataflow Gen2. The closest strategy to achieving this is by using templates or copying queries, which requires the same logic to be applied to a new Dataflow Gen2.
Ideal For: Data ingestion solutions that contain data sources originating from multiple sources and require many transformations. The learning curve will be low for developers currently working in Power BI that are transitioning to Fabric. Data can be easily refreshed into a data warehouse or lakehouse, but monitoring and error handling will be limited.
Microsoft Fabric Data Integration – Notebooks
Fabric Notebooks allow data engineers and data scientists to create data-driven solutions using the Apache Spark engine. Many programming languages can be leveraged to read and write data from a wide variety of sources. Developers with coding experience will find this approach familiar as most of the development can be done with Python-based languages.
Fabric Notebook Example Solution
The image below is a screenshot of a data integration solution using Fabric Notebooks:
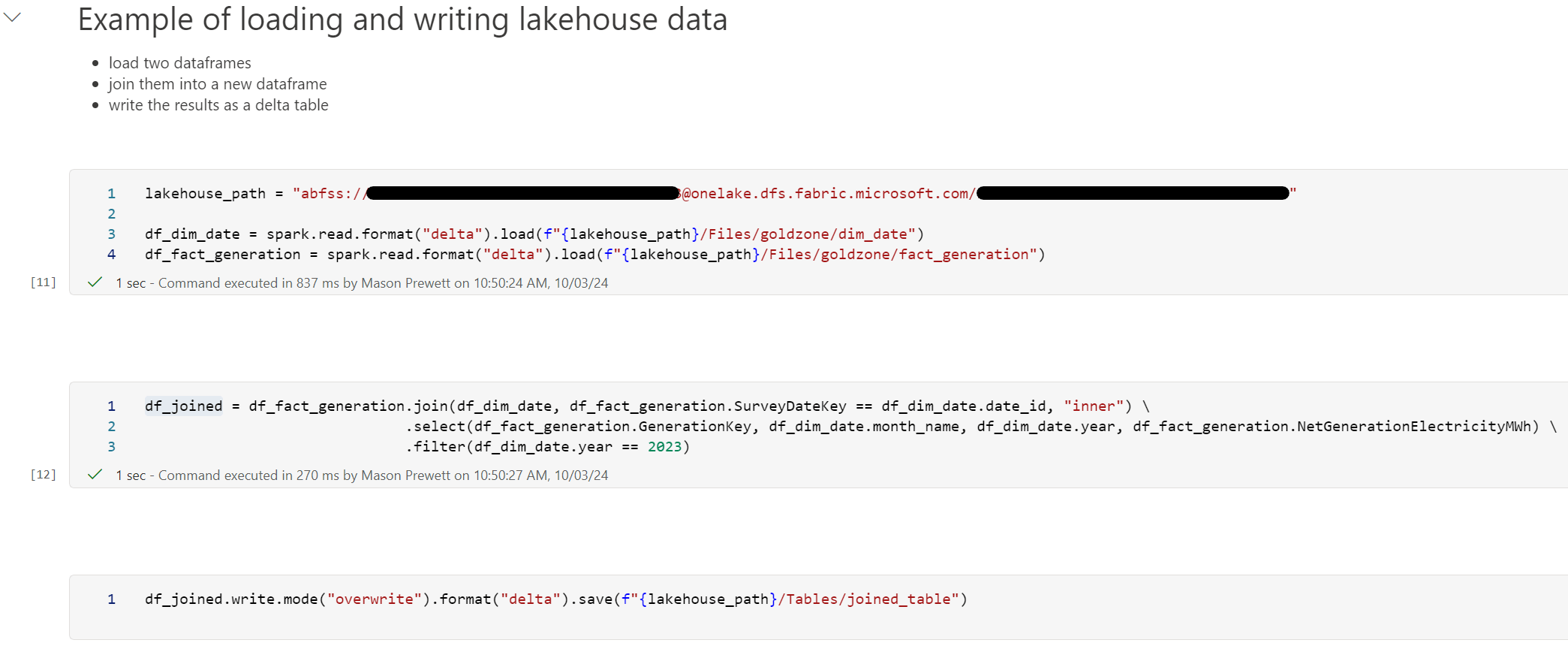
Here’s a high-level description of each step in the solution:
- Markdown text is added at the top of the notebook to provide context.
- A variable is created to set the lakehouse path that will be used for reading and writing data.
- A date dimension is loaded into a dataframe named df_dim_date.
- A fact table is loaded into a dataframe named df_fact_generation.
- The following transformations are applied to this data and loaded into a new dataframe named df_joined.
- An inner join is applied to df_fact_generation and df_dim_date.
- Only the columns needed are selected.
- The results are filtered.
- The transformed dataframe df_joined is written back to the lakehouse.
Advantages of Fabric Notebooks
Fabric Notebooks offer many powerful capabilities for data integration solutions, such as:
- Scalability – the Apache Spark engine is known for its ability to scale well and handle large datasets using massively parallel processing.
- Flexibility – Fabric Notebooks offer the most functionality with being able to customize a data integration solution to fit any need with custom code.
- Code Reuse – Fabric Notebooks are extremely modular, making code reusable and eliminating the need to rewrite common operations. Notebooks support functions and parameters and can execute other notebooks easily.
- Many Languages – Fabric Notebooks offer a wide variety of programming languages to choose from for developing data solutions. The programming language can also be changed as many times as needed during a notebook execution, ensuring that the best tool for the job is always being used.
- Documentation – markdown text allows plain text to be formatted using markup language. Any cell of a notebook can be converted from code to markdown, allowing it to be used to provide context or documentation for code. This replaces code commenting and is much more user-friendly to consume.
- Data Science – Fabric Notebooks are the best option for data scientists in Fabric as they provide an ideal environment for machine learning, experiments, and modeling.
Limitations of Fabric Notebooks
There are also some limitations of Fabric Notebooks, such as:
- Learning Curve – the flexibility that Fabric Notebooks provide does come at a cost. They have the highest learning curve of all data integration methods, as it requires a team of developers skilled in data integration strategies and Python. Traditional SQL developers will find this method the most difficult to get started with.
- Scheduling – Fabric Notebooks do have the ability to be scheduled, but this functionality is limited. Scheduling a notebook to run in a data pipeline will offer much more functionality and visibility into execution.
- Can Be An Overkill – using a Fabric Notebook for simple tasks can be an overkill. For example, it is much easier to copy data with no transformations using a data pipeline than it is to write code to achieve this and then schedule it in a data pipeline.
Conclusion
Microsoft Fabric offers great options for data integration with Data Pipelines, Dataflows Gen2, and Fabric Notebooks. All of these tools have a web-based development environment inside of Fabric, eliminating the need to download applications or set up development machines. Each tool has its own purpose: Data Pipelines are great for orchestrating an end-to-end process, Dataflow Gen 2 is a low-code/no-code data integration method, and Fabric Notebooks offer the most flexibility for data engineers and data scientists. Solution requirements will dictate the path to success for a data solution, so choosing the best data integration method should be a key step in project planning.
