By: Shannon Nagy
Are you a mid-career Microsoft-based data integration or ETL/ELT professional who has not yet migrated operations to the cloud and are still trying to orient yourself in the post-on-premises data landscape?
Perhaps you have spent the last decade or so attempting to master SQL Server Integration Services (SSIS) and possibly even the earlier Data Transformation Services (DTS)… only to wake up and realize that the technology you still use daily is now sixteen years old, and you are on the brink of becoming a dinosaur.
If any of that resonates with you, then welcome to the club and hopefully this article will help! The main cloud-based tool that you will need to learn is Azure Data Factory.

Azure Data Factory provides ways to ingest data with a large number of connectors, ranging from databases to files to web services to protocols and more. You connect to these various data sources by creating an object called a Linked Service.
Once the linked service is defined, a Dataset object is created, which represents the structure within the data store that can be accessed by activities. Activities are commands that include data movement and transformation logic. An integration runtime joins the activity to a linked service by providing the compute environment for it to dispatch from and/or run.
For starters, you will likely use a copy activity from on-premises to the cloud, landing in a Data Lake, or Blob storage. Then, probably some transformations such as filtering, aggregating, etc. via SQL stored procedure, query, or script, and possibly even some initial analytics. These activities are grouped together logically to form pipelines, so they can be managed and monitored as a unit.
Pipelines can either be scheduled or triggered by the occurrence of certain events. Parameters, such as a dataset or linked service, are defined in the pipeline and used by the activities within, upon the execution, or pipeline run.
Orchestrating pipeline activities is done with Control Flow, which may include sequencing or branching activities, defining the parameters and passing arguments into them, or for-each looping containers.
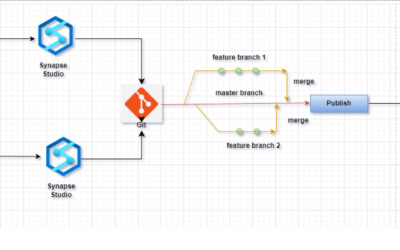
Once all transformations are complete, the final data set can then be published to another linked service (data destination) like Azure Data Warehouse or Azure SQL Database for downstream consumption by other tools, such as Power BI. Pipeline operations can be developed and deployed with Azure DevOps and Github, for continuous integration.
For those of you who are visual learners, this Microsoft graphic may be useful.
Questions?
Thanks for reading! We hope you found this blog post useful. Feel free to let us know if you have any questions about this article by simply leaving a comment below. We will reply as quickly as we can.
Keep Your Data Analytics Knowledge Sharp
Get fresh Key2 content and more delivered right to your inbox!
About Us
Key2 Consulting is a boutique data analytics consultancy that helps business leaders make better business decisions. We are a Microsoft Gold-Certified Partner and are located in Atlanta, Georgia. Learn more here.