

By: Mark Swiderski
In Part 1 of our series on this topic, Key2 Consulting discussed how electrical power generation data from the U.S. Energy Information Administration (EIA) was used to create a Power BI dashboard that pulled data from a dimensional model stored in an Azure SQL database.
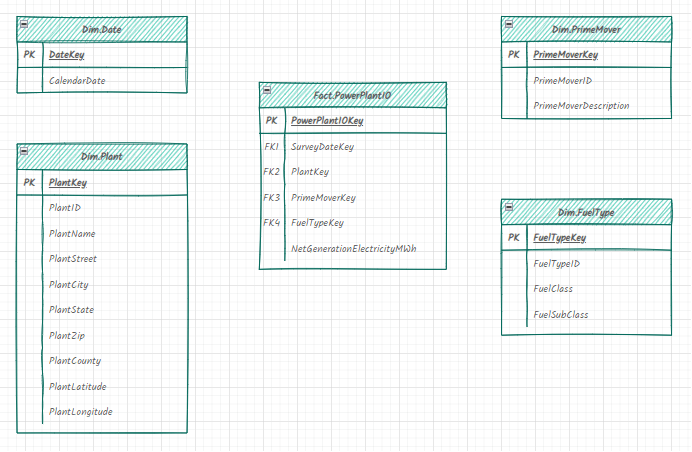
The dimensional model itself was populated with data from Excel files that are published periodically on the EIA’s website. Specifically, forms EIA-923 and EIA-860 were downloaded manually, then extracted and transformed using a combination of T-SQL and SSIS (SQL Server Integration Services).
This initial “quick and dirty” approach was deliberate, as it allowed us to easily profile and validate eight years’ worth of historical data, develop a dimensional semantic layer, and finally, create a robust Power BI dashboard that provides a wealth of interesting insights into power plants, utilities, and energy trends.
We have since revisited the data acquisition and engineering components for this dashboard and have created a programmatic solution that is configurable and dynamic and uses Azure resources from start to finish.
Lakehouse in Azure Data Lake Storage
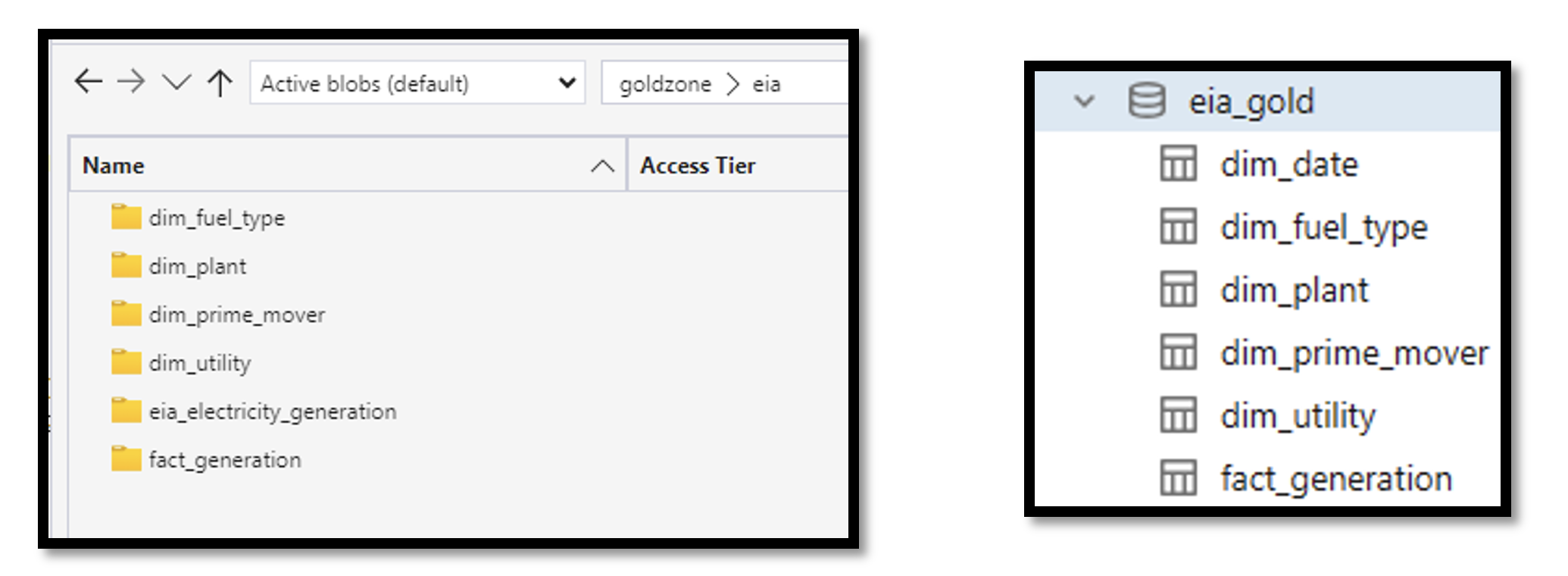
The data source for the dashboard is now entirely built on a lakehouse medallion architecture that resides in Azure Data Lake Storage (ADLS). You can read more about this design pattern here, but the short story is that electrical power generation data is progressively improved as it moves through the three layers of the lakehouse. The gold zone in the lakehouse is where the previously mentioned dimensional model now resides. Instead of Azure SQL tables, delta tables and underlying parquet files are used to store the fact and dimension data consumed by the dashboard.
API Data Source
Electrical power generation data, which was previously sourced manually via forms EIA-923 and EIA-860, is now acquired using the EIA’s free RESTful API. Azure Databricks was used to develop Python notebooks that call the API in a dynamic, parameterized fashion. These notebooks both read and write to JSON configuration files that store details about the extract window, extract type (historical vs incremental), watermarks, target storage account, and more.
After execution, these notebooks generate a multitude of raw, unprocessed JSON files that are placed in the landing zone of the lakehouse. The landing zone is simply a temporary space for accumulated source files before these files are processed into the bronze zone by the next step in our Azure integration solution.
Azure Databricks and Delta Live Table Pipelines
In addition to the notebooks that call the EIA API, Delta Live Table (DLT) pipelines were created in Azure Databricks to consume, explode, and perform basic transformations on the stream of JSON response files generated by the API notebooks. DLT pipelines turned out to be an ideal, performant, and low code solution for the task of consuming a large number of JSON response files.
The DLT pipelines first explode the JSON files into delta tables that reside in the bronze zone, then apply basic transformations and cleansing operations on the bronze zone data that is then merged into delta tables in the silver zone. These silver tables now easily support the transformation logic that will be used to refresh the dimensional model in the gold zone.
Mashup Data from Other Sources
The EIA API does not currently provide detailed data about electric utility companies, so we needed to source data (such as yearly residential customer counts) from other sources. Luckily this historical utility data is located on the EIA website in the form of Excel files, which can easily be converted to CSV.
We also want the ability to support currently unknown future analytics needs, where delimited files from non-EIA data sources (such as Air Quality Index data from the EPA) can be easily landed in the lakehouse and mashed up against the dimensional model to support ad-hoc and machine learning analysis by data analyst and data science personas.
Template-Based Integration Framework in Azure Data Factory
To support the requirement of loading mashup data from flat files, a template-based data integration framework was created using a combination of parent-child pipelines in Azure Data Factory (ADF) and a metadata repository that is hosted in Azure SQL database. The metadata repository stores source/target mapping information, such as source file key columns, source file delimiter, target partition attribute(s) and target storage account location (to name just a few).
This source/target data is passed to the pipelines at execution time so that only a single generic parent-child template pipeline combination was created to load data from one or more delimited files. It can run concurrently or sequentially, depending on which execution group number has been assigned to the child pipeline.
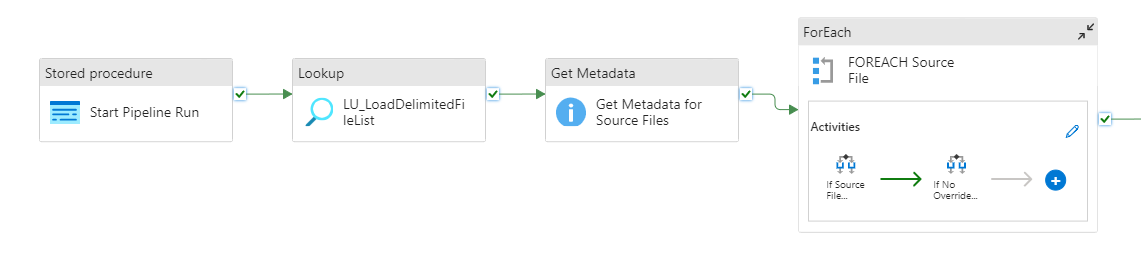
The framework is also capable of ETL/ELT auditing and will capture details such as row counts, execution status, and execution duration.
Azure Data Factory as An Orchestrator
Azure Data Factory (ADF) pipelines were developed to orchestrate, schedule, and execute the notebooks used to call the EIA API as well as execute the notebooks used to refresh the dimensional model in the gold zone. The pipelines also invoked other Azure resources like Azure Key Vault (used for secret management) and Azure Logic Apps to generate an email notification if a pipeline failed during execution.
Summary
While this blog post was a 50,000-foot overview of the overall methodology and the key data engineering technologies in Azure, the next posts in this series will take a deeper dive into each Azure resource that was mentioned above. Key2 Consulting is also evaluating how Microsoft Fabric, which recently entered general availability in November 2023, can be used to implement an equivalent data engineering solution for the same EIA source data. Stay tuned for the next post!
Keep Your Data Analytics Knowledge Sharp
Get the latest Key2 content and more delivered right to your inbox!
