Author: David Thomas
Background
This client faced significant challenges in managing the ingestion and distribution of terabytes of data from multiple sources while maintaining data integrity and providing rapid access to mission critical data. The organization required a robust, unified solution to facilitate the ingestion of data in diverse formats and from diverse sources into a secure, accessible, cloud-based system while ensuring a seamless distribution to on-premise endpoints.
Challenge
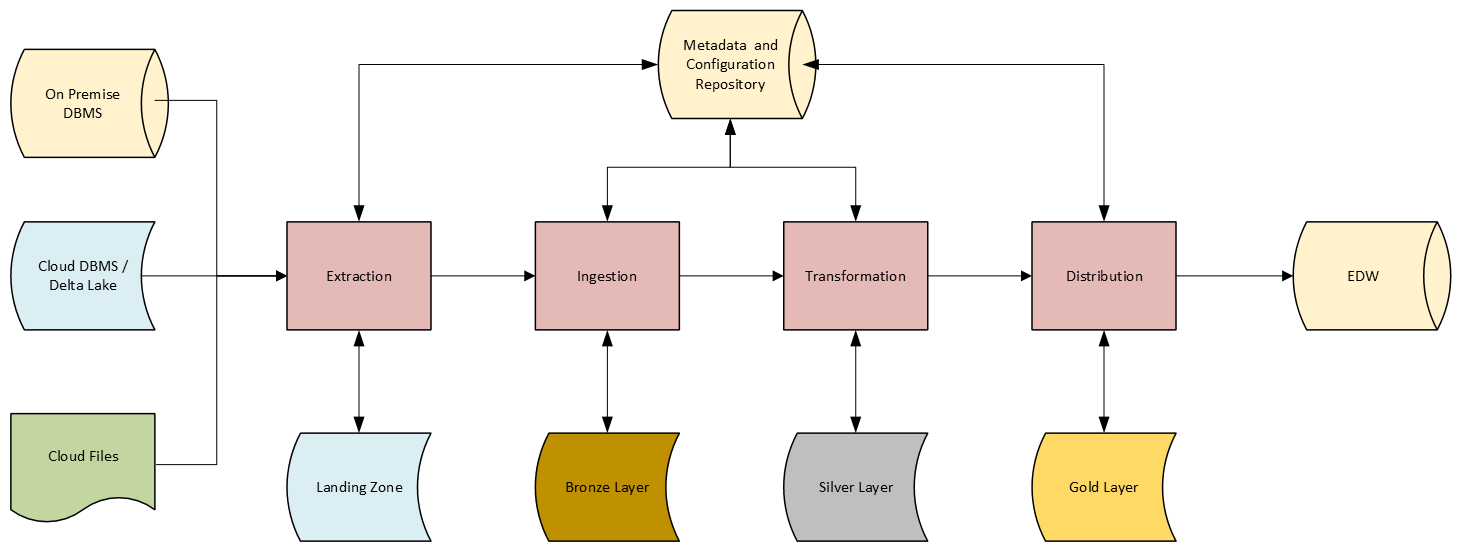
The core challenge revolved around the necessity to ingest large volumes of data from disparate sources, which came in various formats. The solution had to maintain strict separation by source system but also rapidly apply multiple levels of highly specific, customized, complex transformations before delivery. The resulting data had to preserve the prescribed format of the existing Enterprise Data Warehouse used for analytics workloads. It also needed to simultaneously deliver the latest data to the a cloud-based system that would allow more rapid access while mimicking the EDW’s architectural conventions.
SPECIFIC REQUIREMENTS INCLUDE:
- Ingesting data into a cloud-based system from various sources.
- Performing complicated data transformations to meet various analytical needs.
- Delivering data to both an Azure-hosted Delta Lake and an on-premise server for further distribution.
- Table versioning to support schema changes over time both at the source and in the destinations.
These challenges presented a demand for a streamlined, integrated solution capable of effectively managing the entire lifecycle of data processing and distribution that also allowed for dynamic, metadata driven, configurable, complex transformations.
Solution
To tackle these challenges, a comprehensive cloud-based solution was developed leveraging Microsoft Azure Data Factory and Azure Databricks. This solution implemented the following:
- **AzureSQL**An Azure SQL database was utilized for hosting a repository of metadata, process configurations, and transformation details.
- **Azure Data Factory** ADF wasutilizedto synchronize metadata from on-premise SQL Server instances, pull data securely from on-premise servers, deliver data securely to on-premise servers, schedule pipeline executions, coordinate execution of Databricks notebooks, and log results.
- **Azure Data Lake Storage** ADLS was selected as the storage solution forthe DeltaLake. This involved extracting changes into a landing container, ingesting incoming changes into a bronze layer, and then performing additional transformations as necessary to proactively maintain referential integrity for late arriving data.
- **Azure Databricks** Once data was extracted into the landing container, Databricks notebooks generated surrogate identifiers tracked across table versions, stubbed out placeholder records to maintain referential integrity for late arriving data, and applied the necessary transformations as the data was processed from the bronze to the silver and then gold layers.
Results
The implementation of this integrated cloud-based solution yielded substantial benefits for the client:
- Efficiency: The new process significantly reduced the time required to ingest and transform data, leading to quicker insights for decision-making.
- Scalability: With Azure Data Factory and Databricks, the solution was easily scalable, allowing for effective handling of increasing data volumes without degradation in performance.
- Flexibility: The ability to manage multiple source formats, multiple destinations, and any variety of intermediate transformation ensured that the solution could adapt quickly to changing business needs.
- Enhanced Reporting: The seamless, rapid integration of incoming changes to the Delta Lake and EDW improved the accessibility of data across the organization, enabling better-informed decision-making.
Conclusion
The innovative solution developed not only addressed the immediate challenges related to data ingestion, transformation, and distribution but also positioned the department for dramatic expansion of the systems use as new source data from new systems needed to be integrated into their EDW rapidly and processed efficiently. By harnessing the power of Azure Data Factory and Databricks, Summit Integration Process transformed its data management capabilities into a competitive advantage in today’s data-centric landscape.