
By: Andy Kim
I was at the SQL Saturday Atlanta conference last week and attended a session in which the speaker asked the audience,
“Has anyone here used fuzzy grouping or fuzzy lookups in SSIS?”
To my surprise, I was the only one who raised their hand.
When data cleanly matches (when the join column values match exactly), regular SQL joins should be used to find matching records. But when data has slight variations, we need another tool. This is where fuzzy logic comes in to play.
Fuzzy logic matches similar strings together and there are two main types: fuzzy grouping and fuzzy lookups. I believe mechanisms such as REGEX and SOUNDEX are used under the hood.
Fuzzy grouping works well to de-duplicate records from within one data set where the matches are not necessarily exact, thus called “fuzzy” matches. I have used fuzzy grouping to de-duplicate customer data coming from multiple sources. I have also used fuzzy lookups to assist in account reconciliation during a salesforce conversion – but that topic will be for another blog post! I will be focusing on fuzzy grouping in this blog post.
Here is an example data problem. “Johnny J Crowne” and “John J Crowne” are showing up as two separate customers in reporting when in actuality John should be one customer. Another example might be “Susanna Saylors” vs. “Suzy Saylor”. Your needs could be any number of entity variations that needs de-duplication, such as inventory, where products names are slightly different even though they are the same product. Aggregations about these entities are incorrect, resulting in bad reporting. And no one wants bad reporting!
A Demonstration of Fuzzy Grouping
Let’s put together a basic example of fuzzy grouping. We will take sample customer record data from three different sources, union them, and run them through fuzzy grouping (as shown below).

I have mocked up sample customer data for 3 systems. You might notice that there are slight variations in the records. Names are spelled differently, street address names aren’t identical, certain sources are missing email data or address data, etc.
Source 1

Source 2

Source 3

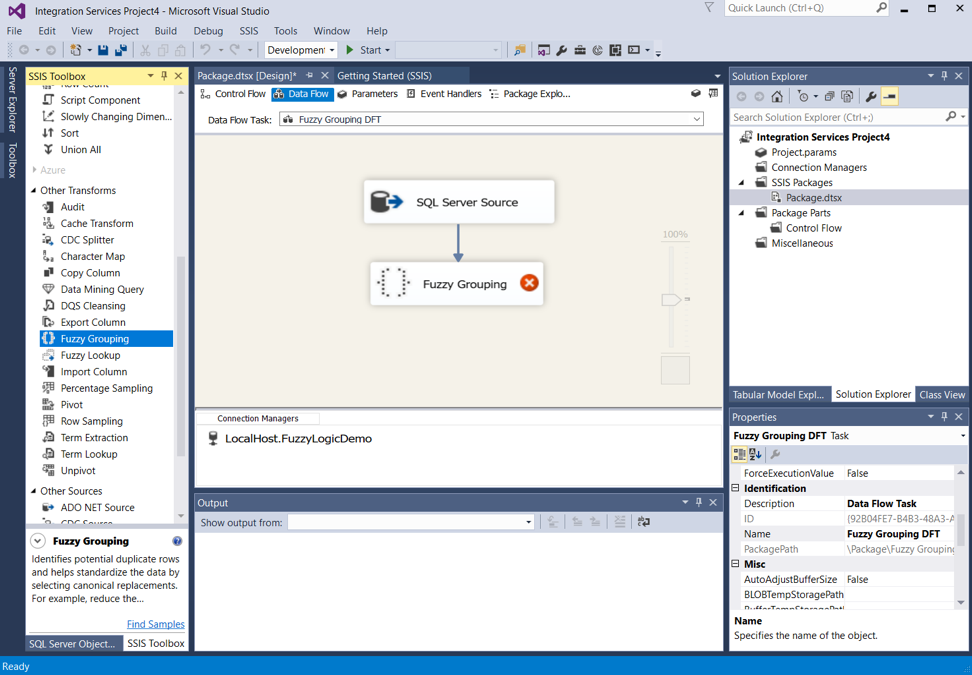
I opened up a new SSIS package and added a data flow task to the control flow. The fuzzy logic tasks only appear under the context of a data flow.

I open up the data flow task we just added, added a SQL server source, and linked it to a fuzzy grouping task.

The Anatomy of the Fuzzy Grouping Task
Let’s open up the fuzzy grouping task and see what’s inside. The first tab is “Connection Manager,” which is self-explanatory – select/setup a source connection. Note: this task uses temporary tables that are proportional to the input data size. You want to make sure there are enough resources to handle that.

The “Columns” tab is a critical one where you configure the matching algorithms.
1) Check each column that you would like to use in the matching. You may also mark a column as “Pass Through” if you do not want to include it in the matching process but would still like to push the data through the flow.
2) Set the matching parameters on the bottom half of the screen. You can set parameters for each match column you selected on the top of the screen.
-
a) Output Alias – the output name of the match column after the transformation
b) Group Output Alias – the name of the corresponding potential match column value
c) MatchType (Fuzzy,Exact) – fuzzy allows for tolerance, while exact means the column must match exactly
d) Minimum Similarity – a decimal value between 0 and 1 that represents a minimum similarity percentage of this row and its potential matching row. The output will only include values that fall within these similarity tolerances.
e) Similarity Output Alias – the name of the output column that will contain the values for the similarity values for the match columns
f) Numerals – determines if leading/trailing numerals in the string are significant. This is used for situations like street address strings.
g) Comparison Flags – these hold some advanced matching options like case sensitivity

The “Advanced” tab is where you can set the following:
-
a) Input Key Column Name – the name of the system-generated key for each incoming record
b) Output Key Column Name – the name of the system-generated key for the potential match record
c) Similarity Score Column Name – the name of the column for the Overall Similarity Score
d) Similarity Threshold – a slider that is adjusted to eliminate matches that do not match above a certain threshold based on the overall match similarity
e) Token Delimiters – delimiter configurations

After configuring these settings, I hooked the fuzzy grouping task up to a new table destination.

Executing the Package and Examining the Results
Let’s take a look at the output table after executing the package. This particular matching algorithm uses FirstName, MiddleInitial, and LastName columns to match, but in reality, there could be several other match types such as:
-
– Email and Telephone
– FirstName, LastName, Street1, and Telephone
– FirstName, LastName, ZipCode
– Or whatever works best for your data
You can see the output of the fuzzy grouping task below. If the ‘_key_out’ column values are equal, then the records have been matched. I’ve tried to group the matches together (visually) by using blue/white colors. As you might notice, some records did not match. This is where the algorithms and the configuration may be tweaked to achieve the optimum results for your data.
It’s important to know that fuzzy logic is never 100% perfect, although it does a great job when set up correctly. If further precision and accuracy is needed, the results can be fed into a master data management system where a data steward can monitor the matching process and manually make corrections to the data when false matches are produced. This can also be done for records that were supposed to be matched but did not get matched for some reason.
Fuzzy Grouping Output
Here you can see:
-
1) which records matched (according to our matching algorithm)
2) the data from each original source record
3) the suggested “clean” values for each match column
4) the similarity percentage of each match column, and an overall similarity_score

My client solution is more complex than this. It has more sources and I run the data through several different match algorithms because we could get different matches based on those different matching algorithms. After that, I compile the match result data and leverage it to make reporting more accurate.
I hope this example has been helpful in understanding fuzzy grouping functionality.
Lessons Learned
I have learned many useful things throughout my experiences with fuzzy grouping. Here are some of my recommendations:
-
#1 – Be very cognizant of when the input dataset starts getting larger
One thing I would recommend is to start becoming more cognizant of when the input dataset starts getting larger (over a few million rows). When my client’s data spiked 4-5x, we started encountering scaling issues and the jobs weren’t completing. We were able to help control this initially with various indexing strategies and minor tweaks, but in the end, the best solution was to upgrade to a more powerful AWS EC2 machine instance compared to the one we were running on.
#2 – It is best to break down incoming data into its most empirical components
From an architecture standpoint, I think it’s optimal if you can break down the incoming data into its most empirical components. What I mean by this is:
-
• For address data, instead of having
“Street: 1456 Main Street” → “StreetNumber: 1456”, “StreetName: Main Street”,”StreetType”: “Street”
• For Name data instead of having
“Name: John Q Doe” → “FirstName: John”, “MiddleInitial: Q”, “LastName: Doe”
Note: This will not always be possible as there may be a “least common denominator” source that prevents this.
Conclusion
We’ve just walked through an example of the basics of fuzzy grouping. Please feel free to share your experiences with fuzzy grouping, or any lessons you have learned while working with it. I would love to hear them.
For more information, check out Microsoft’s Doc on Fuzzy Grouping.
Keep your data analytics sharp by subscribing to our mailing list!
Thanks for reading! Keep your knowledge sharp by subscribing to our mailing list to receive fresh Key2 content around data analytics, business intelligence, data warehousing, and more!
Key2 Consulting is a data warehousing and business intelligence company located in Atlanta, Georgia. We create and deliver custom data warehouse solutions, business intelligence solutions, and custom applications.