")
By: Mason Prewett, Dean Jurecic, and Mark Seaman
Introduction
Microsoft Fabric was announced during the Microsoft Build conference in May 2023, and many consultants from our company were in attendance to hear the details of this new technology. We were interested in the new capabilities of creating a Data Warehouse in a Microsoft Fabric workspace. The Data Warehouse product is targeted towards developers coming to Fabric from a SQL Server background, as it allows for a development experience like T-SQL. This provides a more seamless introduction to the cloud for those SQL Server users compared to similar Azure services such as Synapse Analytics or Databricks.
In this article, we share the details of our experience with creating an end-to-end Data Warehouse solution in Microsoft Fabric. We used the Microsoft Learn Fabric Data Warehouse Tutorial as our guide and customized each step to fit our needs. The diagram below represents the architecture that was used in our solution, as it is slightly different than the one provided in the guide.
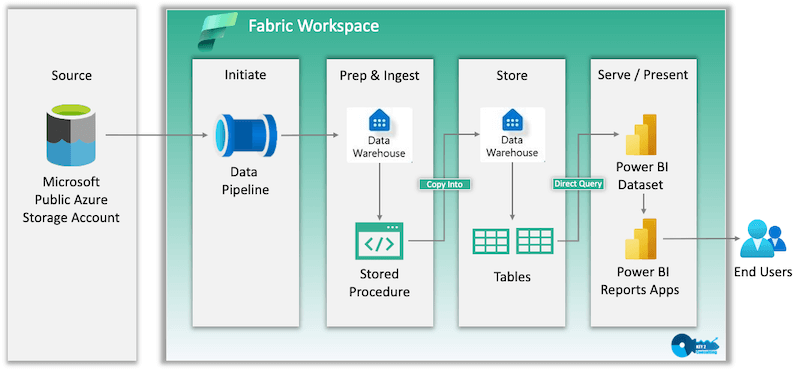
After completion, our solution consisted of the following resources in a Microsoft Fabric workspace:
- Power BI Report – report containing visuals to answer business questions
- Power BI Dataset – auto-generated by Fabric and stays in sync with the data warehouse
- Data Warehouse – data storage, data model, data exploration, and stored procedures
- Data Pipeline – single point of execution used to load data into the data warehouse
Starting a Microsoft Fabric Trial
To work with Microsoft Fabric, a Fabric trial or Fabric capacity is required. Microsoft offers a 60-day trial of Fabric that allows usage of all current features. Please see our previous blog post, How to Start a Microsoft Fabric Trial, for more information.
Creating a Microsoft Fabric Data Warehouse
Creating a Fabric Data Warehouse is as easy as creating a dashboard or report in a Power BI workspace. Open the Fabric trial workspace and click “+New” button and choose “Show all”. This will bring up the page below that shows all available resources that can be created in this workspace. Under the Data Warehouse section, choose “Warehouse”. Enter a name, click “Ok” and the Data Warehouse will be created.
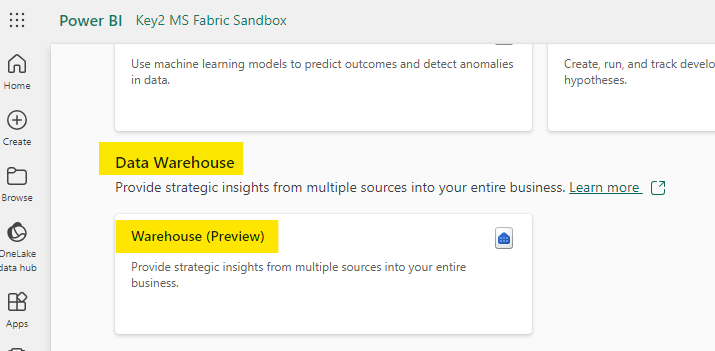
The Default Dataset
When a new data warehouse is created, a dataset will automatically be created in the same workspace. This dataset stays in sync with the data warehouse model. The dataset inherits the workspace permissions, making it seamless for report developers to begin creating reports.
Data Warehouse Permissions
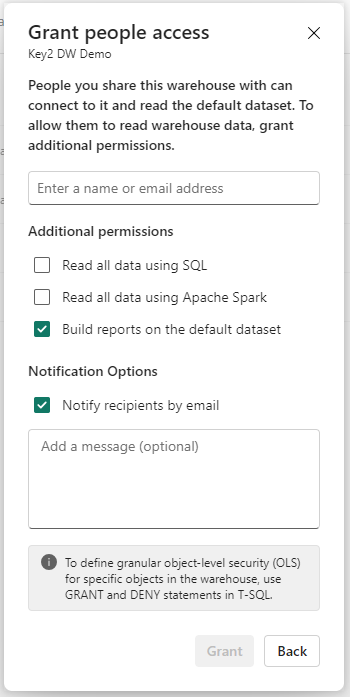
To be able to query or modify the data warehouse directly, additional permissions can be granted by clicking the “Share” button next to the warehouse and using the options in the below image.
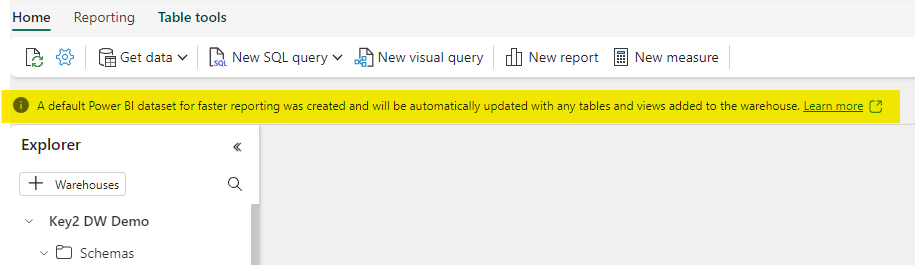
Creating Tables in a Microsoft Fabric Data Warehouse
Creating tables in a Microsoft Fabric Data Warehouse is almost identical to SQL Server (some limitations are covered below). We first created a dim and fact schema, and then created the tables to match our data source tables to be imported. All of this was done using T-SQL.
Data Warehouse Tables are Delta Tables
Data Warehouse tables are created as Delta formatted tables in OneLake. You can see this by using OneLake File Explorer to view the folder structure of the Data Warehouse.

This does affect the functionality of Data Warehouse tables. For example, we were not able to TRUNCATE a table that we created as it returned this error:
“TRUNCATE TABLE is not a supported statement type”
This article describes some of the limitations of the T-SQL Language in Data Warehouses, which does include the TRUNCATE statement. To achieve this functionality, we had to drop the table and recreate it. This makes sense considering that it is a Delta table.
Pro Tip #1: There are some differences in data types between Microsoft Fabric Data Warehouses and SQL Server. Understand these differences while planning out tables.
Pro Tip #2: Microsoft Fabric Data Warehouse tables do have some feature limitations.
Importing Data into a Microsoft Fabric Data Warehouse
We chose to load our tables using T-SQL and the COPY INTO statement. We used the Worldwide Importers DW provided by Microsoft in a public Azure storage account (this was provided in the Fabric tutorial). There were 2 tables loaded:
- dim.city – 116,295 records
- fact.sale – 50,150,843 records
We created a stored procedure in our Data Warehouse that loaded the tables using a COPY INTO statement (example below).
|
1 2 3 4 |
--Copy data from the public Azure storage account to the fact.sale table. COPY INTO [fact].[sale] FROM 'https://azuresynapsestorage.blob.core.windows.net/sampledata/WideWorldImportersDW/tables/fact_sale.parquet' WITH (FILE_TYPE = 'PARQUET'); |
Creating and Scheduling a Data Pipeline in Microsoft Fabric
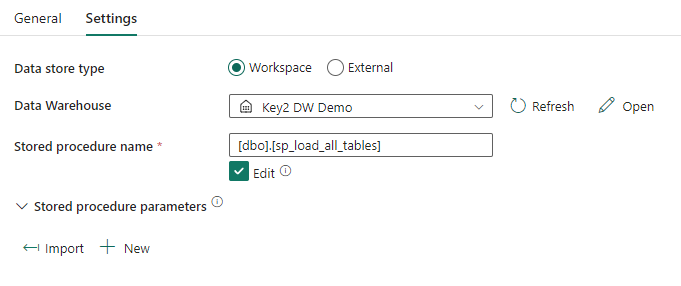
Creating Pipelines in Microsoft Fabric is a similar experience to Azure Data Factory. One improvement is the ability to connect to items directly in the Warehouse, instead of having to use linked services and integration datasets. We used a Data Pipeline in Microsoft Fabric to execute and schedule the stored procedure that loads all tables in our Data Warehouse.
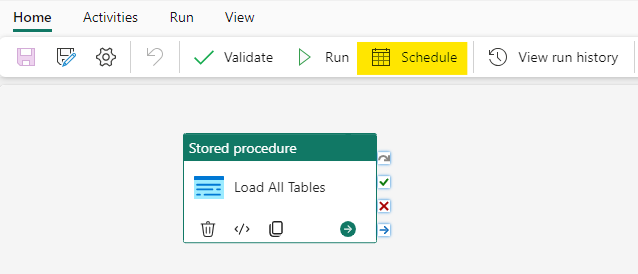
There are two different ways to schedule a Pipeline:
- Use the calendar icon in the Pipeline.
- Use the ellipsis on the Pipeline and choose “Schedule”.
- dim.city – 116,295 records
- fact.sale – 50,150,843 records
- An initial load of both tables using COPY INTO took 1 minute 30 seconds consistently
- Dropping both tables and reloading took 1 minute 35 seconds consistently
- SELECT COUNT(*) FROM fact.sale
- Count: 50,150,843
- Fastest: 452 ms
- Slowest: 1.5 sec
- SELECT TOP 100 * FROM fact.sale
- 1 second consistently
- SELECT COUNT(*)
FROM fact.sale s
INNER JOIN dim.city c
ON c.CityKey = s.CityKey - Count: 50,150,843
- Fastest: 331 ms
- Slowest: 2.4 seconds
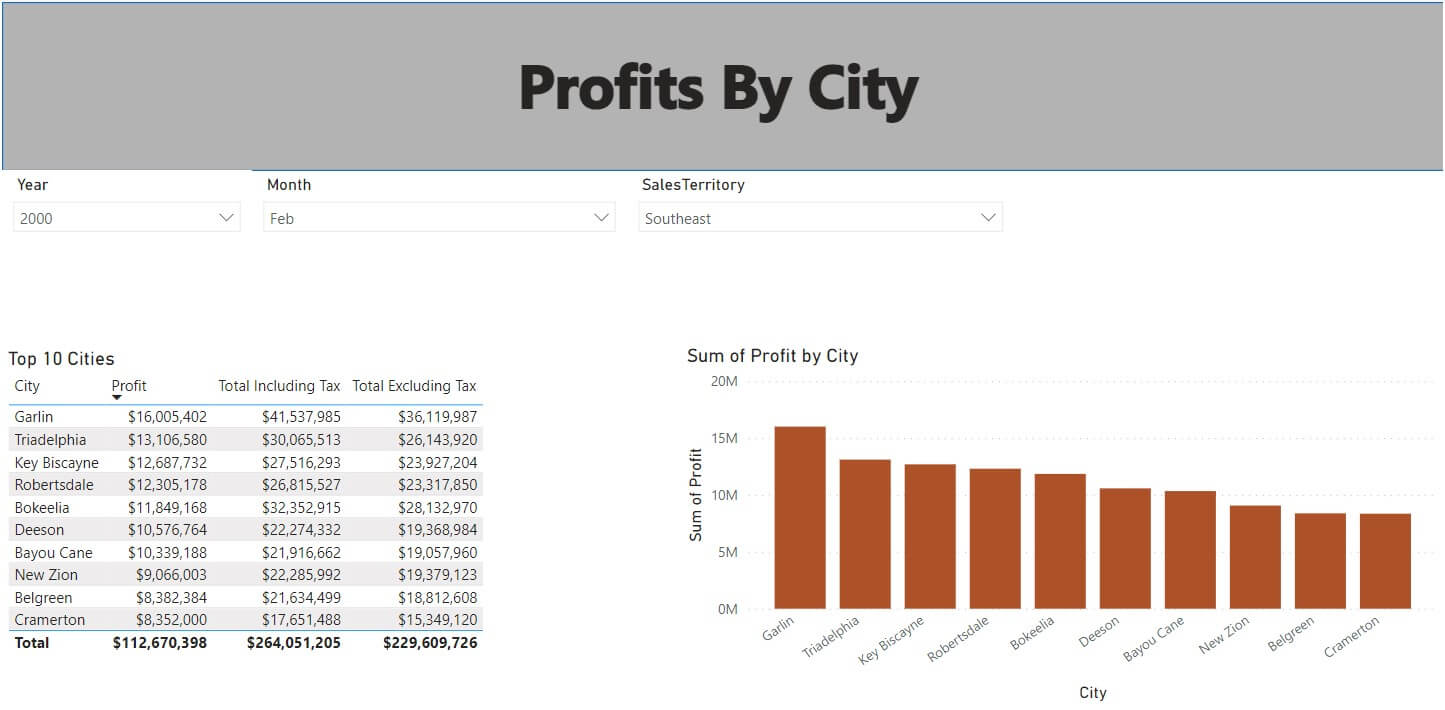
- Using the report in the image below:
- The model uses DirectQuery storage mode
- 4 seconds to initially load the report
- Max of 2 seconds to load results when changing slicer values
Once the schedule is set, the run history can be seen in the Monitoring Hub. Our pipeline called the stored procedure to load all Data Warehouse tables and consistently finished in 2-4 minutes. All of this can be seen in the image below.
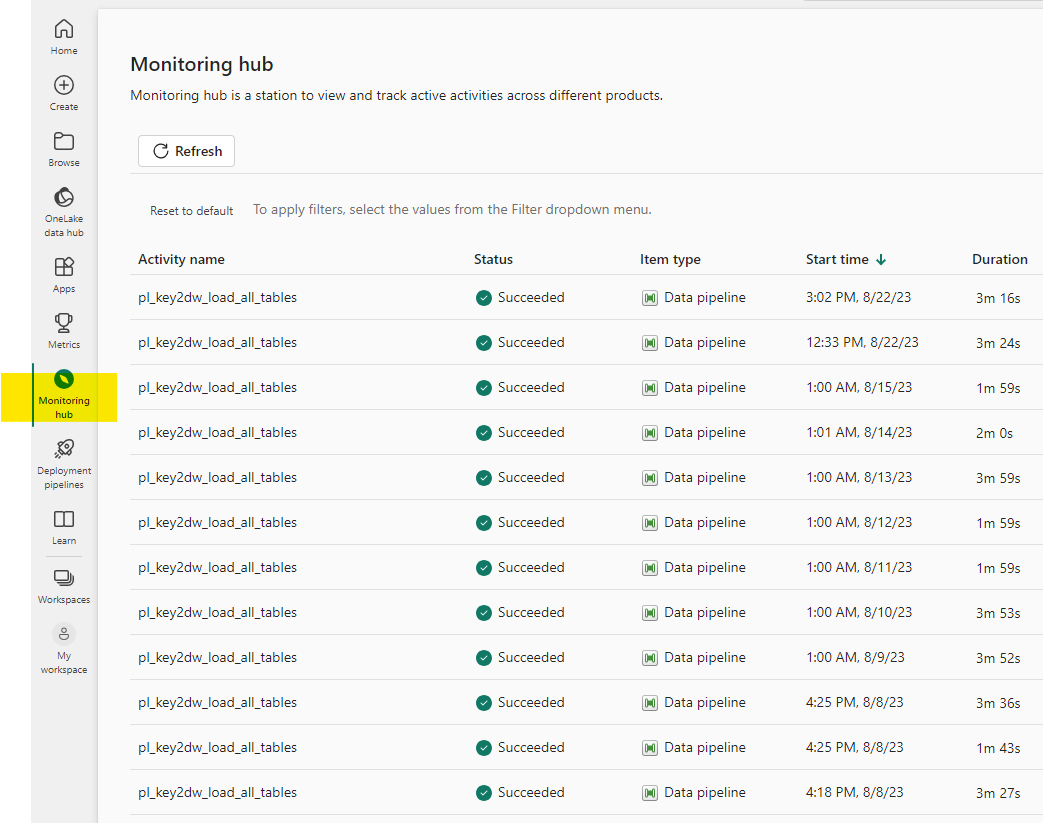
Pro Tip: Fabric can add columns to the monitoring view. For example, the column “Run kind” can be added which shows if it was scheduled or manually run.
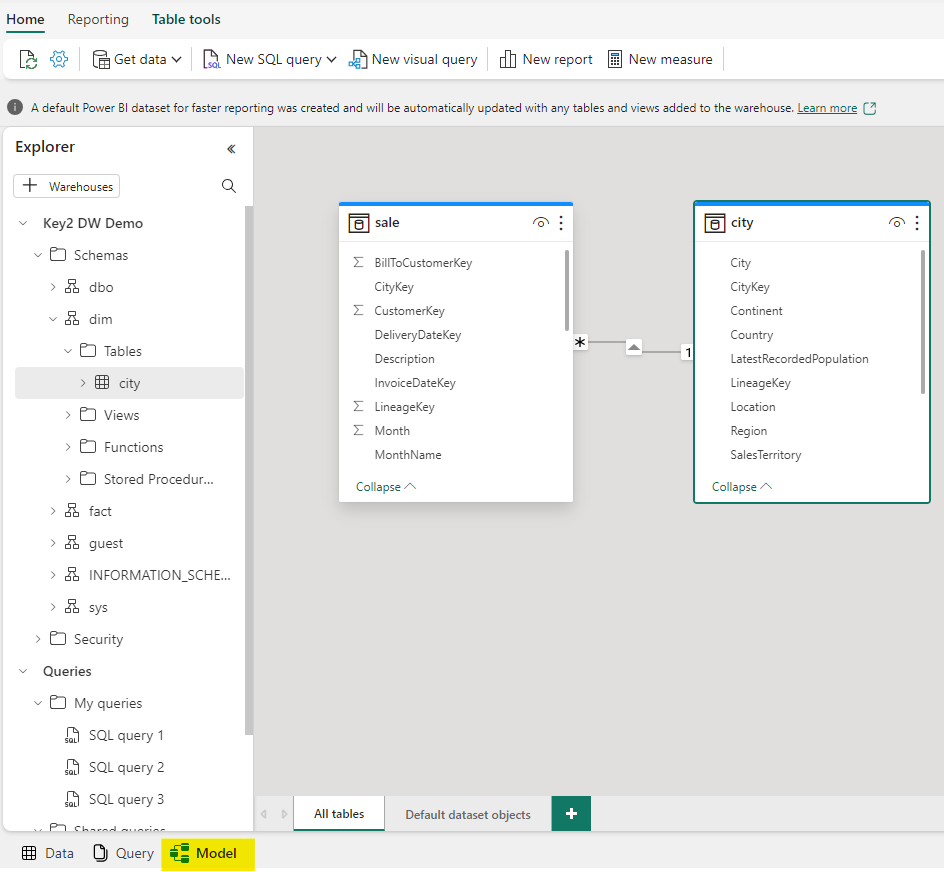
Modeling in the Data Warehouse
Modeling in a Fabric Data Warehouse is a similar experience to modeling in Power BI Desktop. There is a “Model” tab at the bottom of the Data Warehouse UI that will visualize the data model. This allows for management of items such as measures, table properties, and relationships. Any changes made to this model are automatically synced with the Data Warehouse dataset when saved.
Microsoft Fabric Data Warehouse Query Performance
We ran several tests on the performance of Data Warehouse queries and loading data in Power BI. Everything was extremely fast!
There were 2 tables in our Data Warehouse:
Here are our performance stats:
Connect to a Microsoft Fabric Data Warehouse Using Power BI Desktop
When clicking “Get Data” in the Power BI Desktop May 2023 version and later, a section for “Microsoft Fabric (Preview)” appears and offers the ability to connect to Fabric resources.
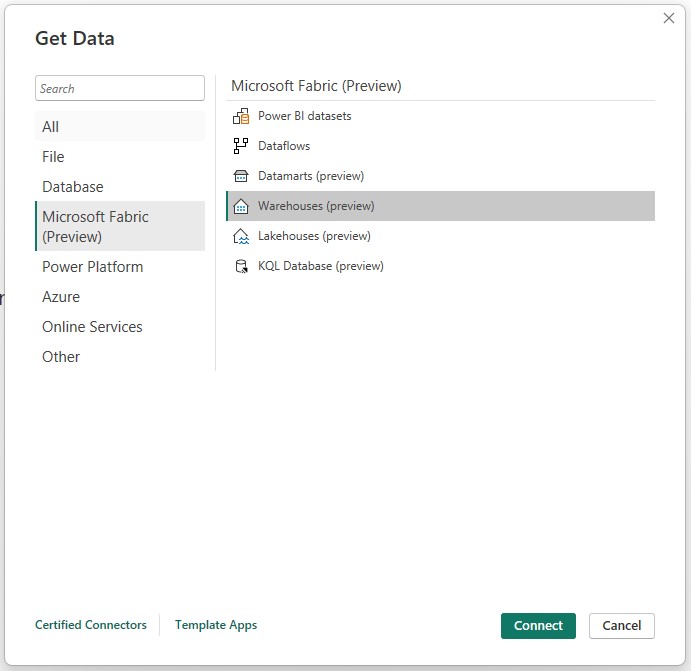
When selecting “Warehouses”, the OneLake data hub is shown and populated with all the Warehouses that the developer has access to.
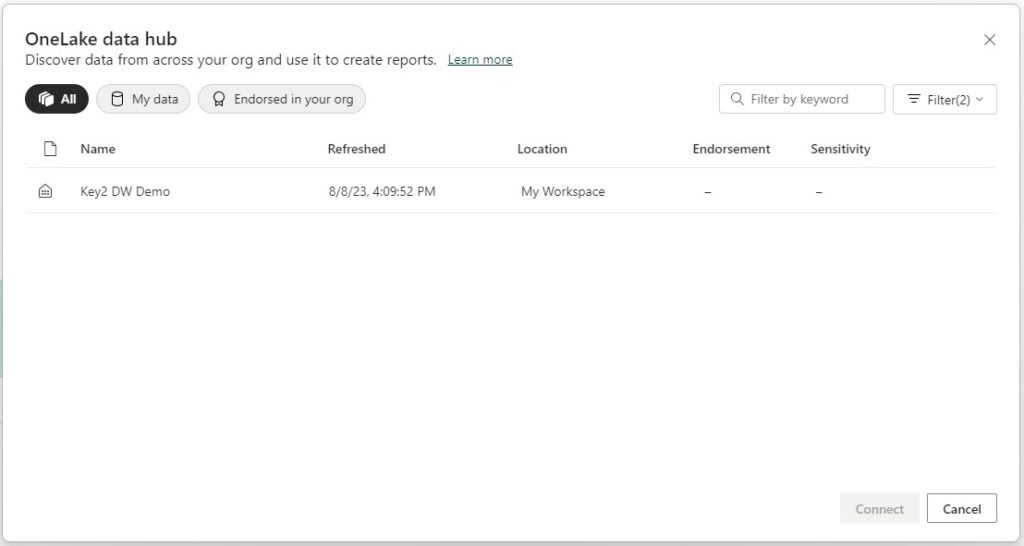
Clicking the “Connect” button automatically loads the Data Warehouse dataset into Power BI Desktop. Connecting in this way automatically sets the storage mode to DirectQuery, which cannot be changed. Navigating to the model in Power BI, the storage mode can be seen by clicking on each table and going to the “Advanced” section of properties. Storage mode is greyed out.
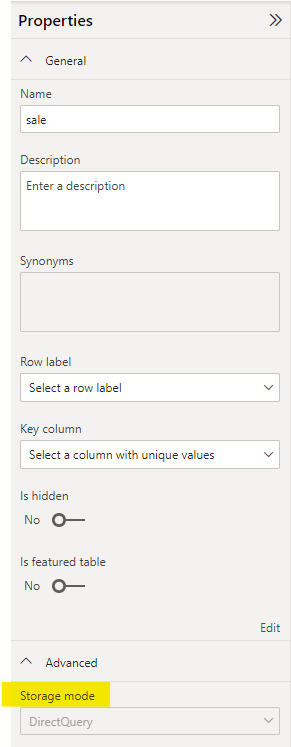
Pro Tip: It is also possible to connect directly to the Data Warehouse using the SQL Endpoint. Connecting in this way allows for either Import or DirectQuery storage modes to be selected. This will require the developer to have direct access to the Data Warehouse and it produces a new dataset when the report is published. This connection can be made by clicking the dropdown arrow on the connect button in the OneLake data hub.
Microsoft Fabric Data Warehouses Cannot Use Direct Lake
We were looking forward to using the new storage mode in Power BI, Direct Lake. However, we were disappointed to find out that Direct Lake is currently only supported for Lakehouse connections and not for Data Warehouse connections. For now, Data Warehouse connections in Power BI are limited to Import and DirectQuery.
Errors Encountered with Microsoft Fabric
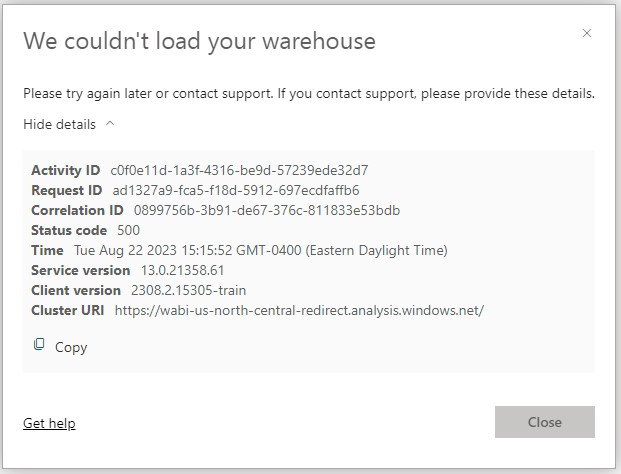
There was one error that we received that corrupted our Fabric workspace. A Fabric trial was started on an individual user’s “My Workspace”, and a Data Warehouse was created. We went through the entire process of creating all database objects, importing data, and setting up a pipeline to refresh. Testing was going well and the data warehouse was ready for reporting. However, we loaded our Data Warehouse the next day only to find this error every time it was opened:
“We couldn’t load your warehouse. Please try again later or contact support. If you contact support, please provide these details.”
After no luck getting past this error, we eventually tried deleting the Data Warehouse and starting over. Everything worked until the default dataset was generated, and then back to this error. It appears to have something to do with the dataset, but it was up long enough to save our code locally. We created a new Fabric trial workspace, and it had no issues.
Microsoft Fabric is still in preview at this time and it is likely that this issue will get resolved before being released fully, but this was still a major setback for our project.
Thanks for Reading! Does Your Company Need Help With Fabric?
Are you looking to get started with Microsoft Fabric? Learn more about our Fabric consulting services here.
Keep Your Data Analytics Knowledge Sharp
Get the latest Key2 content and more delivered right to your inbox!


