")

By: Shannon Nagy
When transitioning from on-premise ETL processes with SQL Server to the cloud with Azure, you may be used to dealing with large numbers of SSIS packages in order to perform data movement operations on many tables at once.
You may have even worked with package templates, BIML, or C# code to help automate and shorten development time. However, the packages themselves still require specific column mappings, which makes it difficult and tedious to automate based on metadata.
Azure Data Factory Pipelines for Azure Migrations
When migrating to the Microsoft cloud, Azure Data Factory pipelines are much friendlier to being dynamically designed and driven by metadata. As an initial example, the main pieces of information required in the metadata table would be full table names for both source and destination (including schema names). This metadata table could be located on-premise, but ideally would be in an Azure SQL Database or Azure Synapse table.
The first step within the Azure Data Factory pipeline is to add a Lookup activity, which will retrieve the list of table names to load into the cloud from the metadata table. That set of table names will then be passed into a ForEach loop activity in order to process each table within the metadata list.
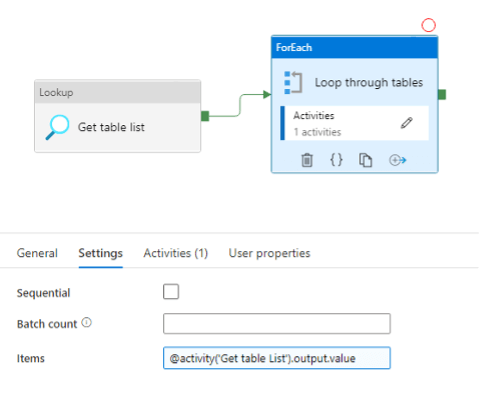
This is achieved by referencing the output value from the Lookup activity in the ForEach settings. If your data can be loaded in parallel, you will want to ensure that the Sequential box is unchecked. This will allow multiple pipelines to be spawned and run at the same time, which will reduce the overall time to complete the data load.
The actual data movement activity will take place within the loop, which could be in the form of a Copy activity, Stored Procedure execution, or Databricks Notebook. If performing a Copy activity, you will need to ensure that your Source and Sink datasets are dynamically referencing any appropriate fields from the metadata table, such as server, database, schema, and table names.
In general, using a stored procedure or Databricks Notebook will be more flexible, since the procedure name or Notebook path can be dynamically referenced in the metadata table.
If you have any questions or would like to see more related content in the future, please feel free to comment below!
Thanks for Reading! Questions?
Thanks for reading! We hope you found this blog post useful. Feel free to let us know if you have any questions about this article by simply leaving a comment below. We will reply as quickly as we can.
Keep Your Data Analytics Knowledge Sharp
Get fresh Key2 content and more delivered right to your inbox!
About Us
Key2 Consulting is a boutique data analytics consultancy that helps business leaders make better business decisions. We are a Microsoft Gold-Certified Partner and are located in Atlanta, Georgia. Learn more here.