Expert Data Warehouse Consulting Services
An excellent data warehouse is vital to data analytics success. We can help you architect and develop a new data warehouse or optimize an existing one.
The Modern Data Warehouse
Our company has a history of architecting, implementing, and loading data warehouses, which has enabled us to build data warehouse consulting expertise based on the following principles:
- Data Collection – creating solutions that source data located both inside and outside an organization
- Data Organization – organizing data in a manner that is conducive to obtaining powerful analysis and positive business actions
- Perform Deep Queries – creating solutions that empower end-users to perform deep queries quickly and accurately
- Data Retrieval – implementing products that enable the retrieval of data at lightning speed and the sharing of it seamlessly across an organization
These principles have served us well in our endeavors over the years, and they have provided a foundation that has allowed us to transition into creating modern, cloud-based architectures for clients. These architectures are crafted around data lakes and lakehouses, with a focus on delivering powerful insights efficiently and effectively.
Data Lakes
Data lakes are central repositories for collecting and storing large amounts of data. This data can range from structured to semi-structured to unstructured. They often contain many different data types.
A key concept of a data lake is that its entities are “schema-on-read.” This requires data to be transformed at the time of analysis (or read) versus the data ingestion process. It gives data engineers wiggle room to customize the way the data is organized, and the schema can be shifted to allow for exploration and analysis by the engineers as well as data scientists.
Tools such as Power BI and Fabric can attach directly to data lakes for deeper analysis. Additionally, our company is well-versed in constructing data lakes in Azure Data Lake Storage (ADLS) Gen2. We use these repositories as the basis for building lakehouses.
Lakehouses
Lakehouses combine features of data lakes and data warehouses to overcome the limitations of data lakes. These limitations include slow query performance, data consistency and security, and data integrity. Lakehouses can overcome these issues with the following:
- Schema Enforcement – A lakehouse architecture defines and enforces a schema to improve query performance and foster easier data analysis by users.
- Data Consistency – Lakehouses support ACID (Atomicity, Consistency, Isolation, Durability) transactions as well as versioning. Companies can implement data quality measures to ensure accurate and reliable data.
- Scalability – Lakehouses are built upon cloud storage accounts which can be easily scaled up to handle increased data volumes. Data integration to shape the defined schemas is based on engines such as Apache Spark. Those technologies are easily scaled by adding additional compute nodes to handle increased workloads.
Similar to data lakes, tools such as Power BI can be used to ingest and analyze these lakehouse models. The primary advantage is that the refined lakehouse model can be imported and used without the need to define schema and shape the data as part of the data import. This makes the model easier to understand and use by less-technical users.
Ready to maximize your Data Warehouse? Contact us today.
We can help your organization architect, build,
or optimize an outstanding data warehouse.
Contact us today.
Our Latest Content

Protected: Our End-to-End Custom Azure Solution – Part 2
There is no excerpt because this is a protected post.

Understanding Power BI Filters, Slicers, & Highlighting
We explore three highly useful Power BI features that enhance data analysis: highlighting, filtering, and slicing.

How to Connect Power BI to Serverless Azure Synapse Analytics
Here’s a solution we created for accessing Azure Data Lake Storage Gen 2 data from Power BI using Azure Synapse Analytics.

How to Use Azure AI Language for Sentiment Analysis
Learn about sentiment analysis in Azure, including how to leverage Azure AI Language services to conduct it.
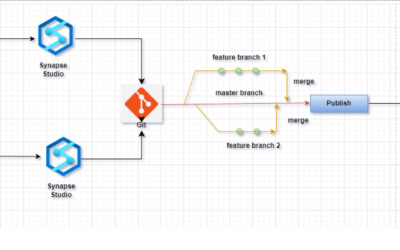
GitHub Source Control Integration with Azure Synapse Workspace
GitHub source control integration with Azure Synapse workspace allows data professionals to manage scripts, notebooks, and pipelines in a version-controlled environment.
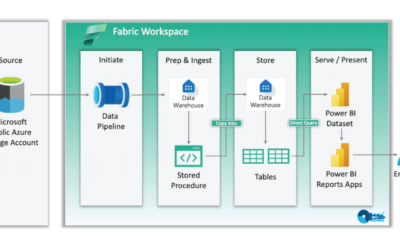
Microsoft Fabric: A Deep Dive into Data Warehouses
We share the details of our experience with creating an end-to-end Data Warehouse solution in Microsoft Fabric.

Key2 Consulting | [email protected] | (678) 835-8539